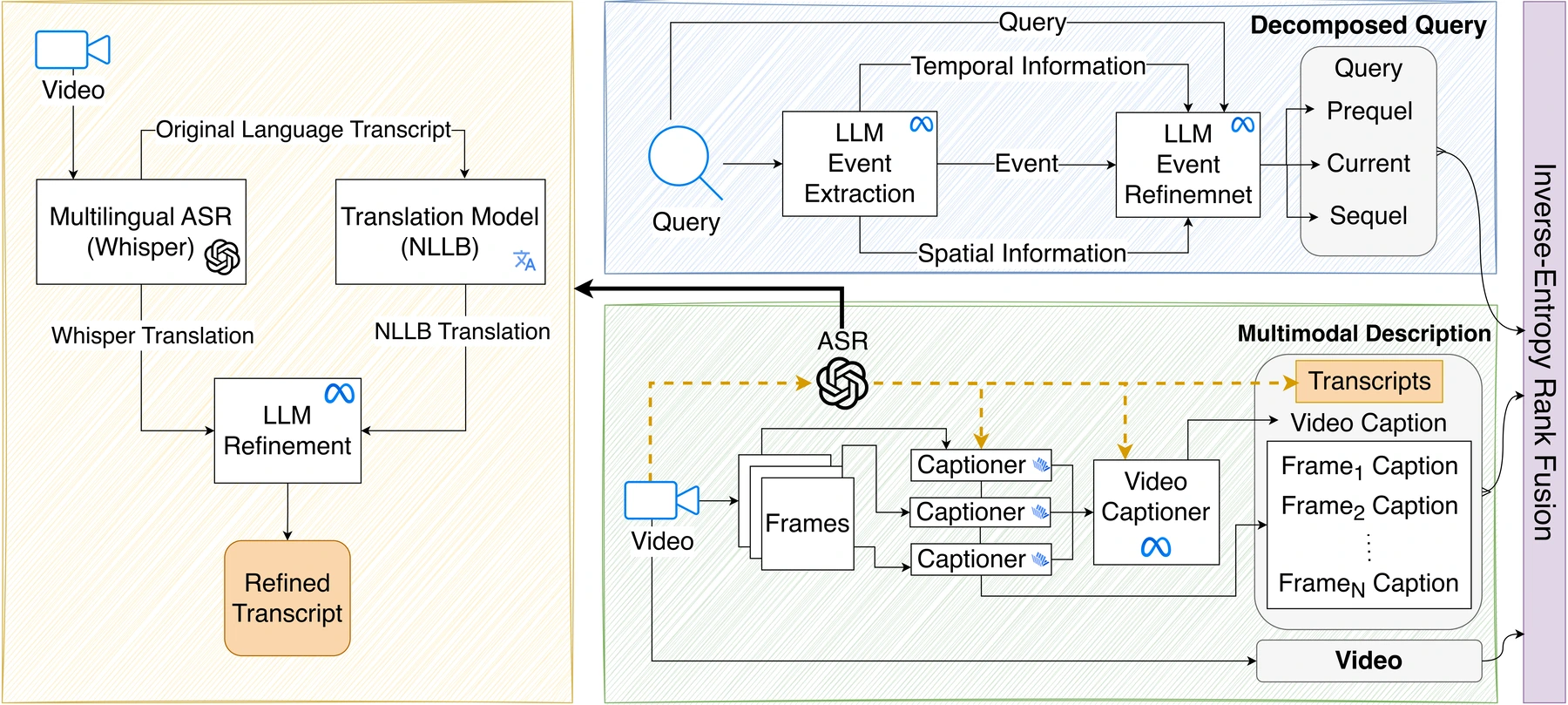
@inproceedings{dipta2025q2equerytoeventdecompositionzeroshot,title={Q2E: Query-to-Event Decomposition for Zero-Shot Multilingual Text-to-Video Retrieval},year={2025},author={Dipta, Shubhashis Roy and Ferraro, Francis},booktitle={AACL},dimensions={true},}
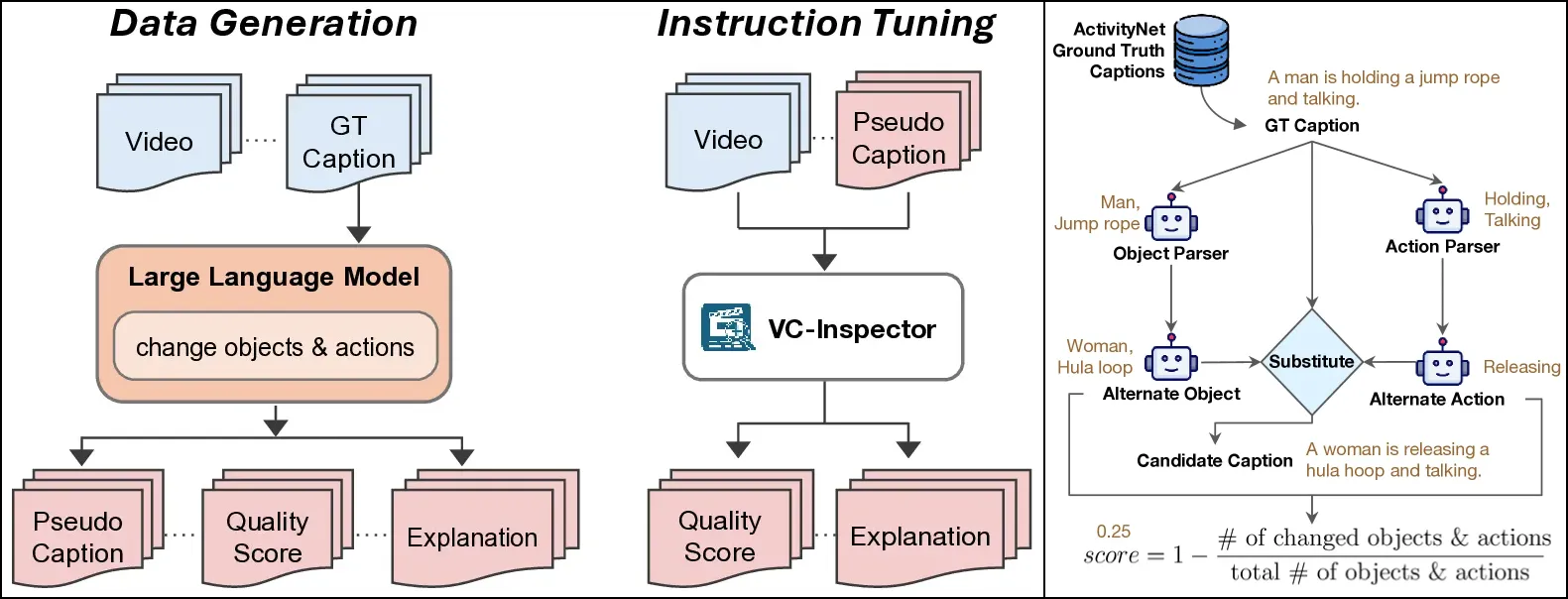
Advancing Reference-free Evaluation of Video Captions with Factual Analysis
Shubhashis Roy Dipta, Tz-Ying Wu, and Subarna Tripathi
@inproceedings{dipta2025factchecker,title={Advancing Reference-free Evaluation of Video Captions with Factual Analysis},year={2025},author={Dipta, Shubhashis Roy and Wu, Tz-Ying and Tripathi, Subarna},booktitle={Preprint},dimensions={true},}
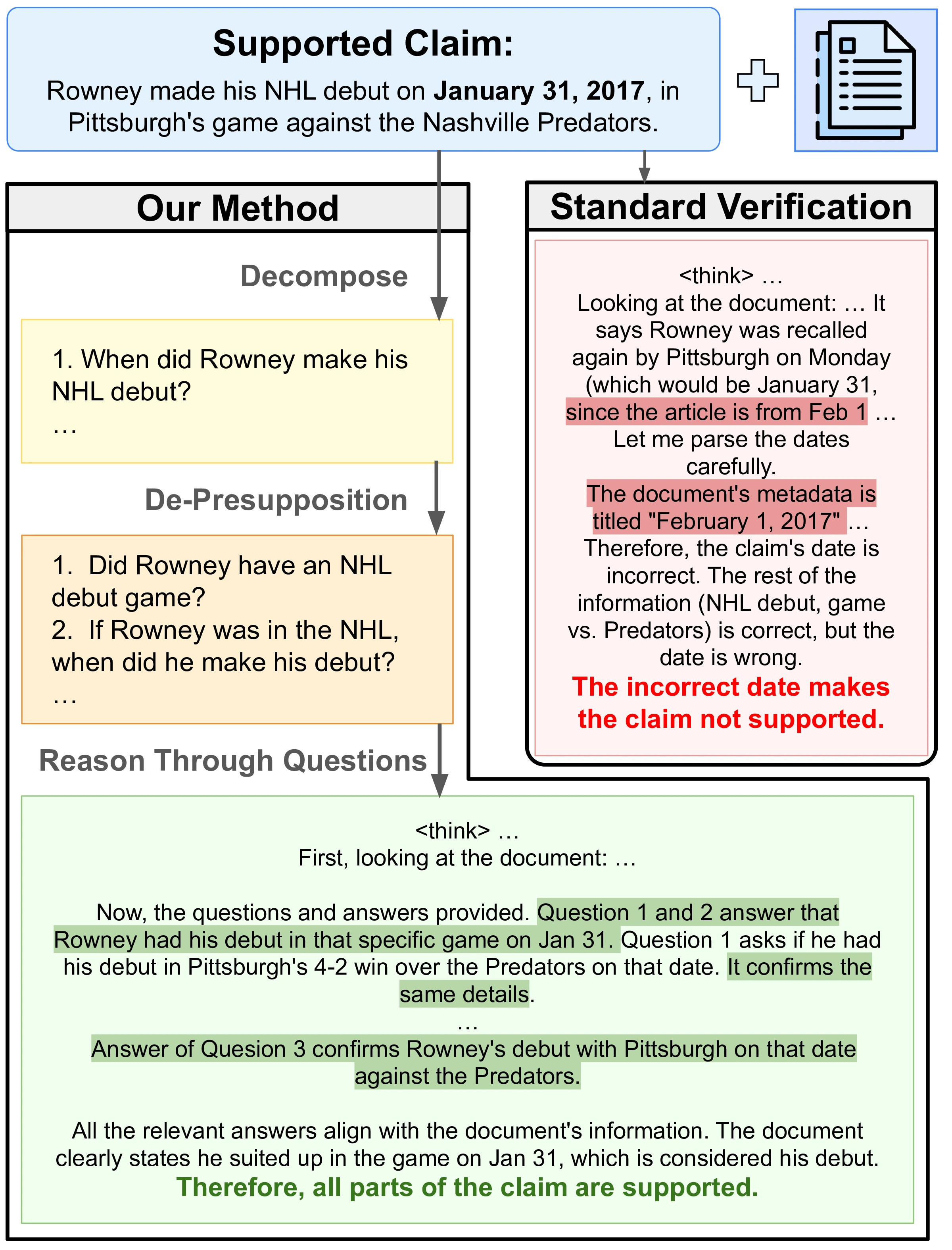
If We May De-Presuppose: Robustly Verifying Claims through Presupposition-Free Question Decomposition
@inproceedings{roy-dipta-etal-2023-depresuppose,title={If We May De-Presuppose: Robustly Verifying Claims through Presupposition-Free Question Decomposition},year={2025},author={Dipta, Shubhashis Roy and Ferraro, Francis},booktitle={*SEM},dimensions={true},}
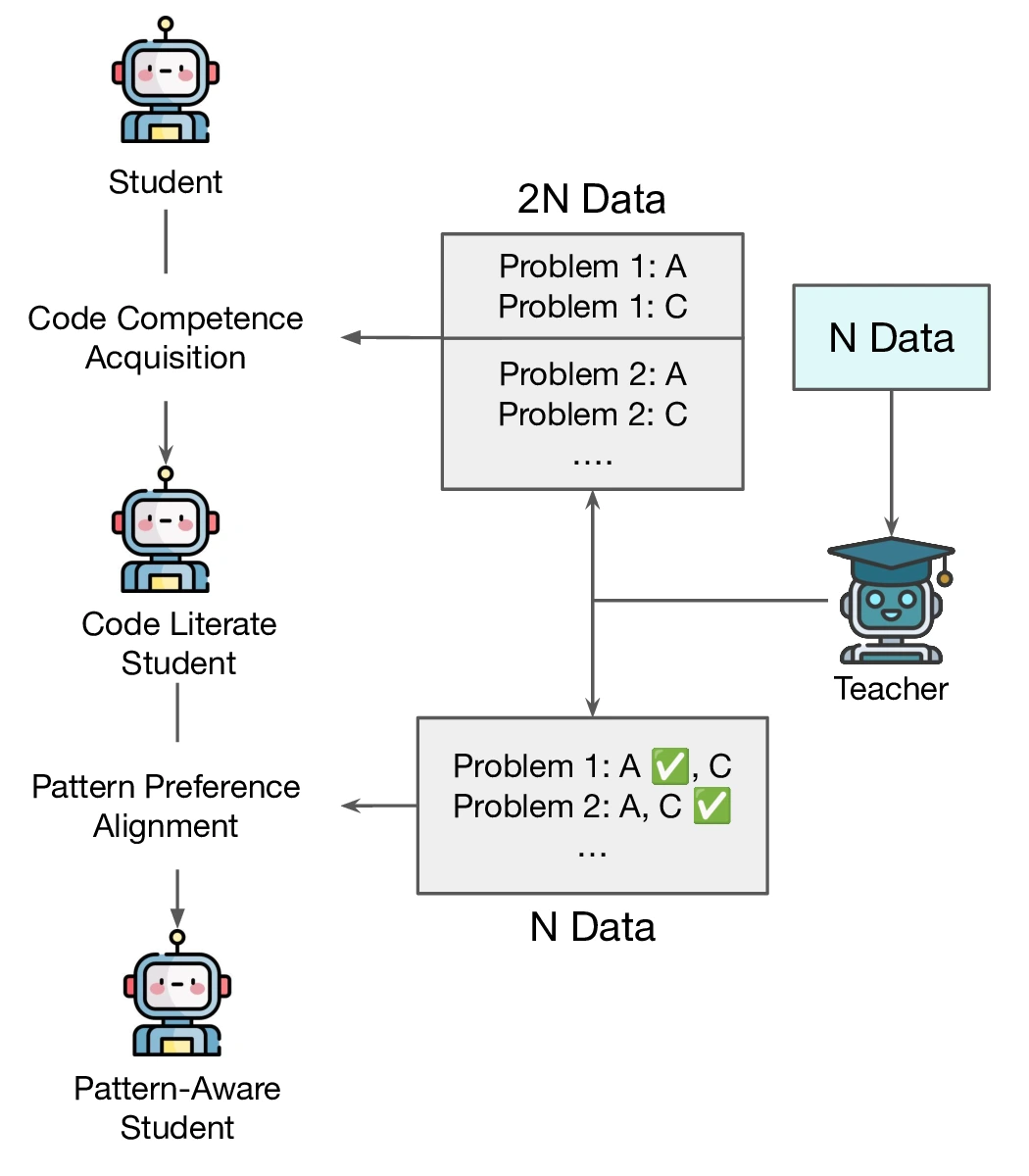
Learning How to Use Tools, Not Just When: Pattern-Aware Tool-Integrated Reasoning
Ningning Xu, Yuxuan Jiang, and Shubhashis Roy Dipta
@inproceedings{dipta2025double_TIR,title={Learning How to Use Tools, Not Just When: Pattern-Aware Tool-Integrated Reasoning},year={2025},author={Xu, Ningning and Jiang, Yuxuan and Dipta, Shubhashis Roy},booktitle={MathAI @NeurIPS},dimensions={true},}
2023
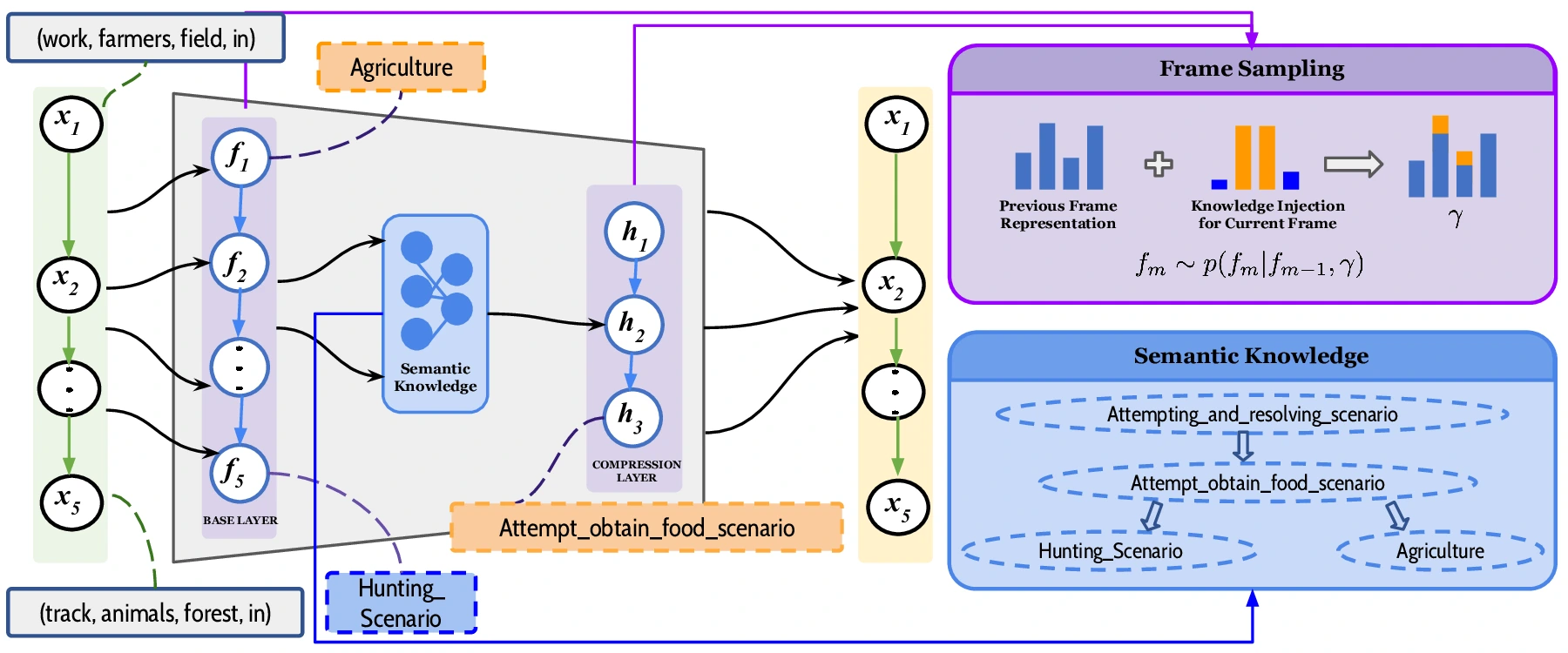
Semantically-informed Hierarchical Event Modeling
Shubhashis Roy Dipta, Mehdi Rezaee, and Francis Ferraro
@inproceedings{roy-dipta-etal-2023-semantically,title={Semantically-informed Hierarchical Event Modeling},year={2023},author={Dipta, Shubhashis Roy and Rezaee, Mehdi and Ferraro, Francis},booktitle={*SEM},dimensions={true},}